Commemorating the Great War
on Twitter
Frédéric Clavert, Asst Professor, C2DH
frederic.clavert@uni.lu
Institute for Historical Research, 7 January 2020
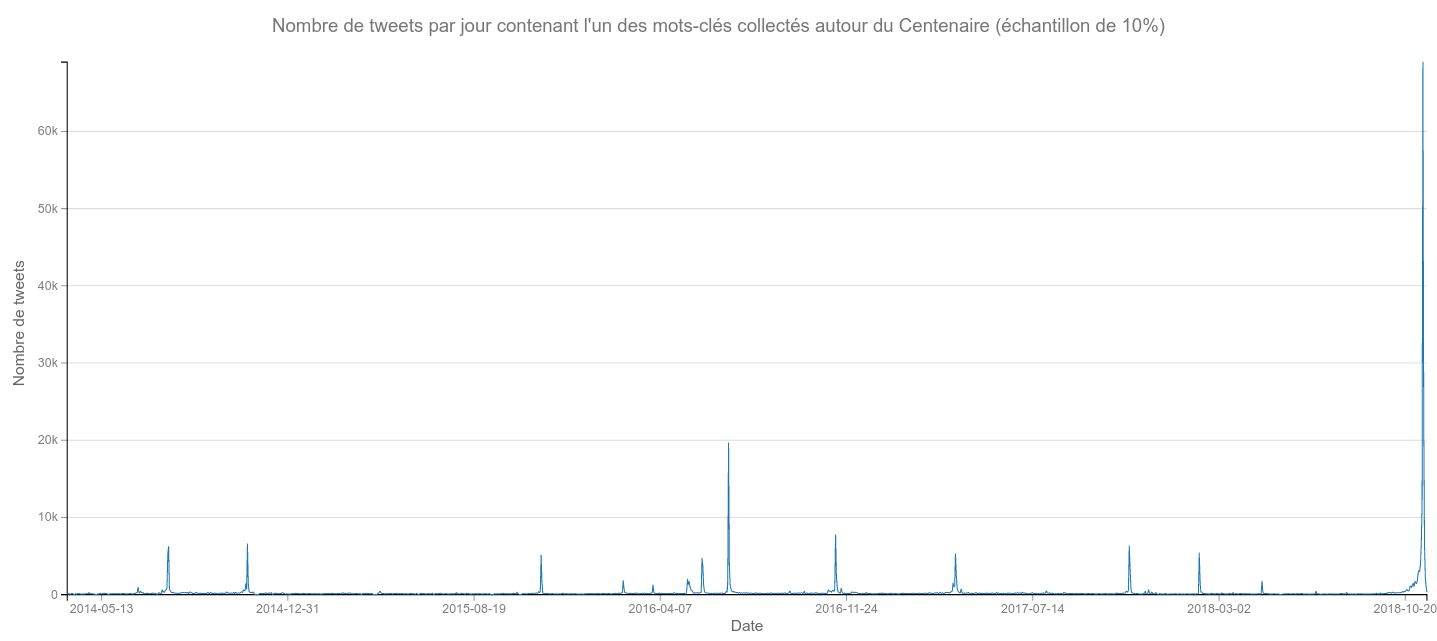
General temporality
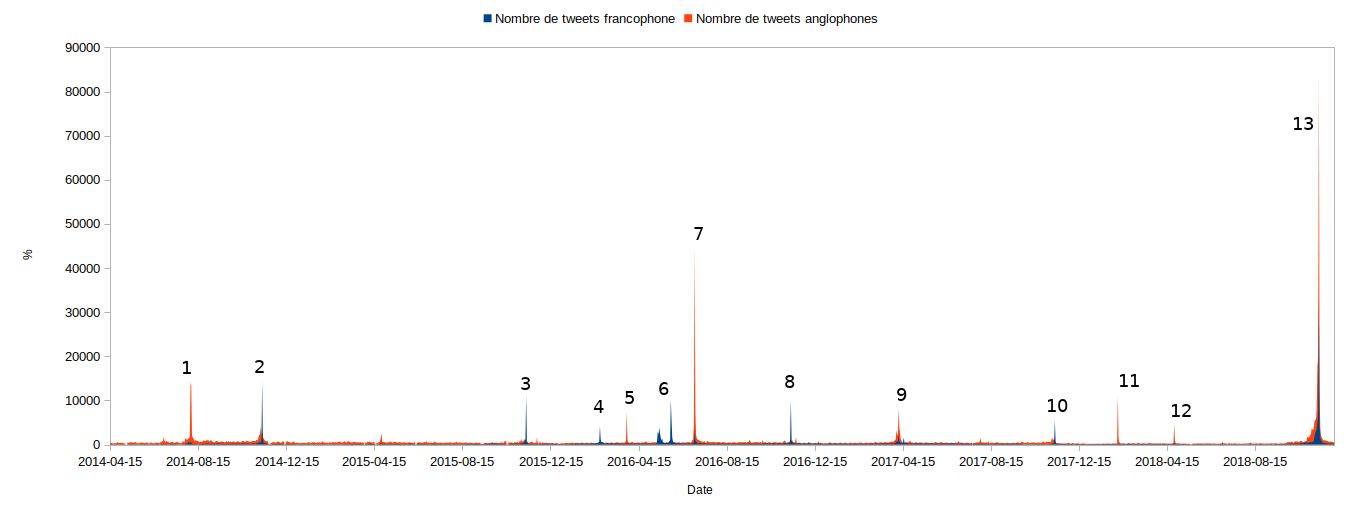
Linguistic temporality
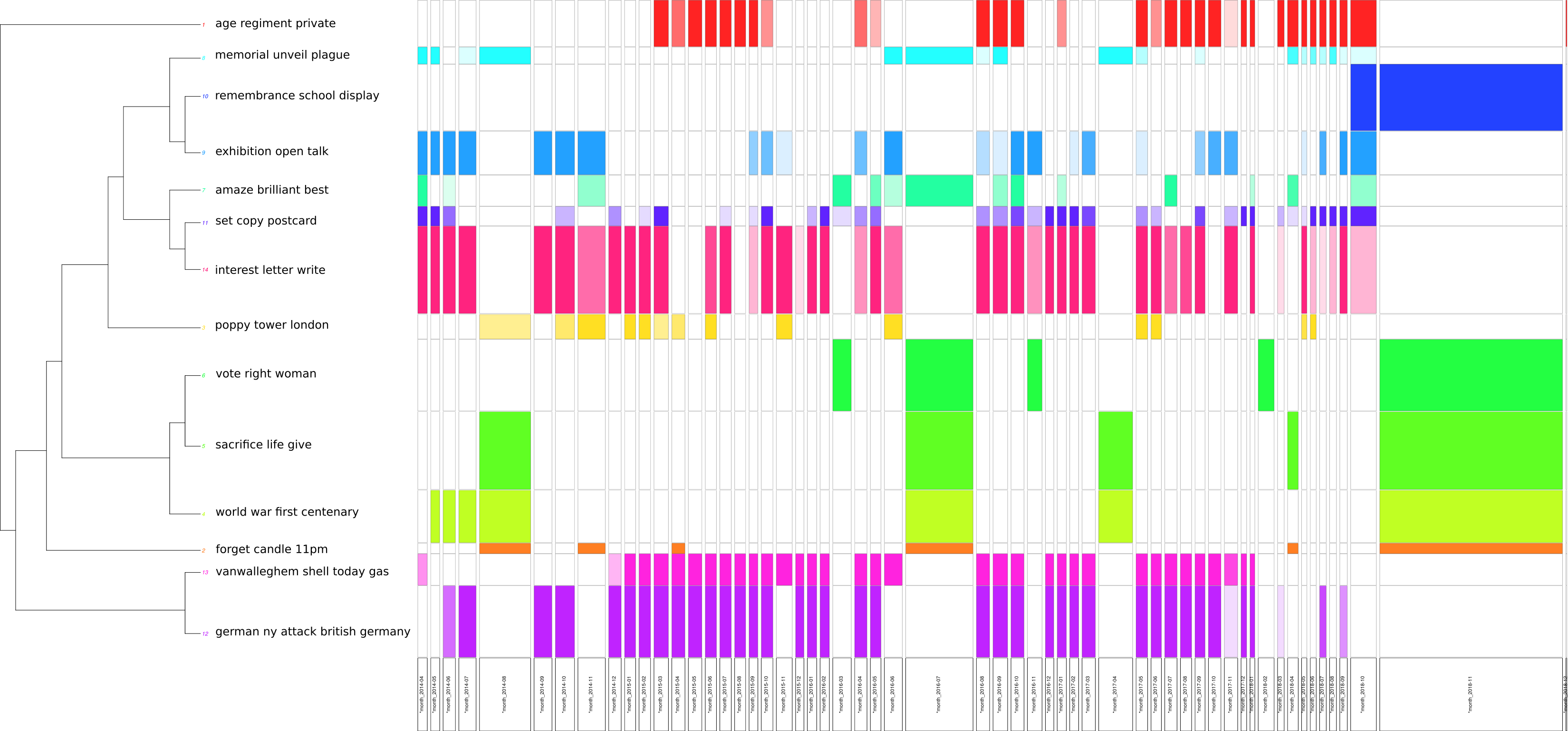
French corpus clustering…

…and its temporality
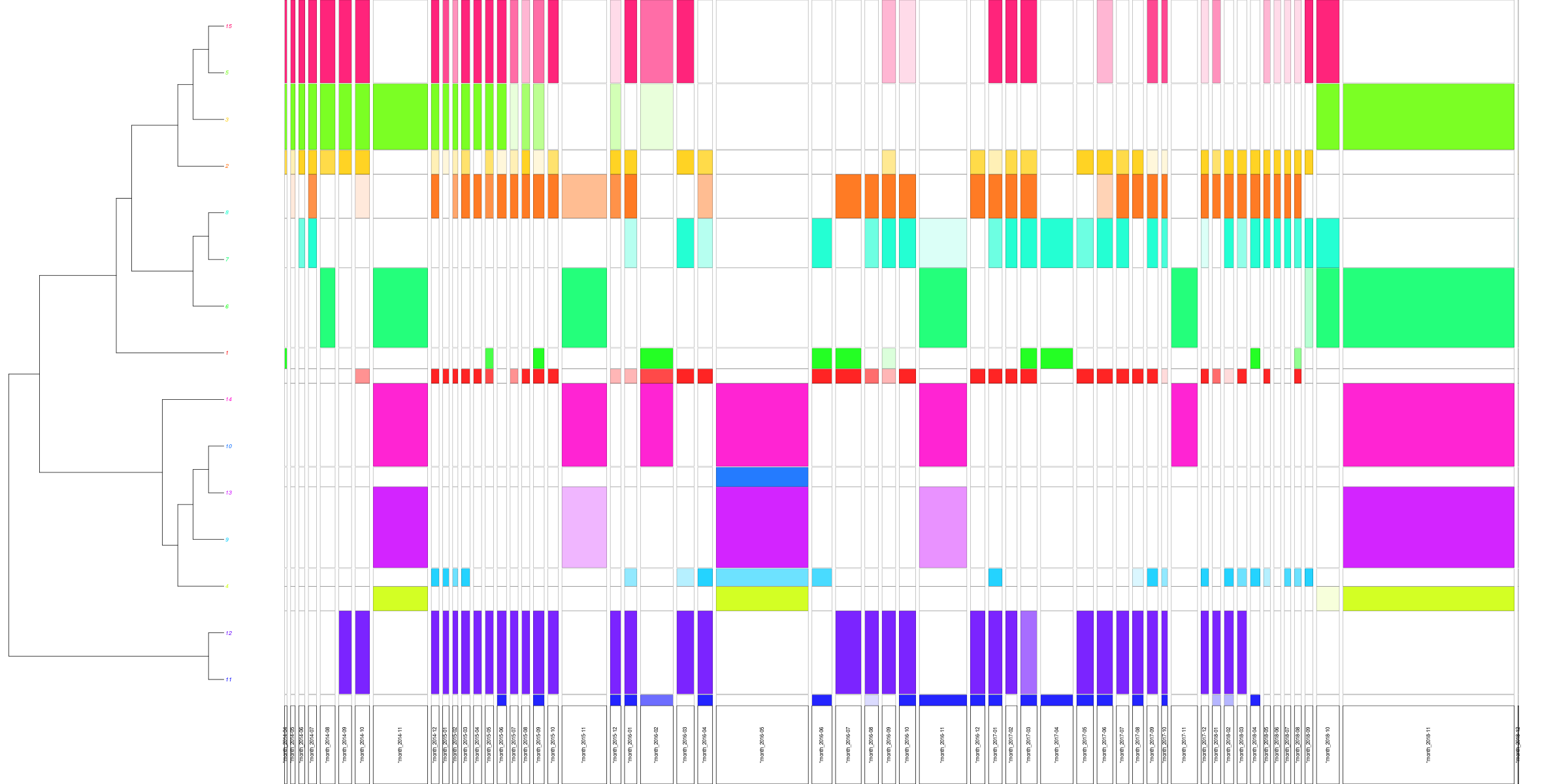
English corpus clustering…

…and its temporality